


作者|阳志平 来源|心智工具箱(ID:Mindnote)
如果将大语言模型想象成一个人,那么,通过对它的人格、智商、理性与社会情绪能力进行心理测量,是不是可以清晰地描绘出大语言模型的心智成熟程度。这就是新兴的人工智能心理测量学。只是,在人工智能心理测量学中,我们不再测查人类,而是测查大语言模型以及各类机器人。
在 GPT-4 发布之后,我们第一时间测查了它在理性思维能力测验上的表现,并将其与 GPT-3.5 的结果、253 位受过高等教育的人进行对比。结果发现,GPT-4 实现了大跃迁,达到了一个超越人类的水准。
在百度文心一言发布之后,我们第一时间获得邀请码,选择了在前文中测试 GPT-3.5 与 GPT-4 一致的题目、流程。详细说明请参考前文。这里不再啰嗦。
简而言之,我们挑选了认知科学家用来评定人类理性思维的四类经典测试任务:语义错觉类任务;认知反射类任务;证伪选择类任务;心智程序类任务。四类任务总计 26 道题目。
在测试之前,我们已经预估文心一言的表现会不如 GPT-4,但最终实际测试结果还是令人大跌眼镜,可能与百度开发团队的认知有关系。在下文中,我会略作分析。
需要提醒的是,本报告仅仅是一个早期工作,并不完善。测试流程有无数可以改善之处。结论未来随时可能被修正、被推翻。各位读者请理解。
现在,让我们来详细看看测试结果。
分项测试结果
在语义错觉类任务这里,我们挑选了 4 个任务。测试结果如下图所示:

文心一言全部答错。其中,第四题未指出错误,只说蒙娜丽莎是达·芬奇的,在卢浮宫。应该是通过百度百科获得了该事实性数据。如下图所示:

认知反射类任务
在认知反射类任务这里,我们挑选了三类任务。
直觉减法操作,测试结果如下图所示:

文心一言答对第一题,其他都答错。尤其是第三题,没读懂题目,在做加法。如下图所示:


直觉序列操作,测试结果如下图所示:

文心一言全部答错。尤其是第一题,没读懂题目,解的是 3 名研究人员发表 1 篇论文要多久。如下图所示:

直觉除法操作,测试结果如下图所示:

文心一言全部答错。如下图所示:



证伪选择类任务
在这里,我选择了经典的沃森四卡片测验。这是一个对于人类来说,超级困难的题目。能够很好地完成这项任务,意味着这个人的理性思维能力很不错。
同样,对于 AI 来说,也是同等困难。GPT-3.5 与 GPT-4 均无法很好完成,同样,文心一言也无法很好完成。测试结果如下图所示:

心智程序类任务
这部分,我挑选了九道题目。这九道题目,是一个更庞大的人类理性思维测验中的一部分。
这九道题目,相对来说较有代表性,代表了人类理性思维知识的方方面面,能够较好地区分理性思维低下与理性思维较高的人。
三个模型测试结果,如下图所示:

文心一言唯一答对的是第二题,但答得也不够好。如下图所示:

而有三道题,要么是答案正确,但是解释错误;要么是同样的提示语,但有时答案正确,有时答案不正确,并且解释不够对。这类测试结果,我们都统一判为错。
而人类被试测试结果如下:
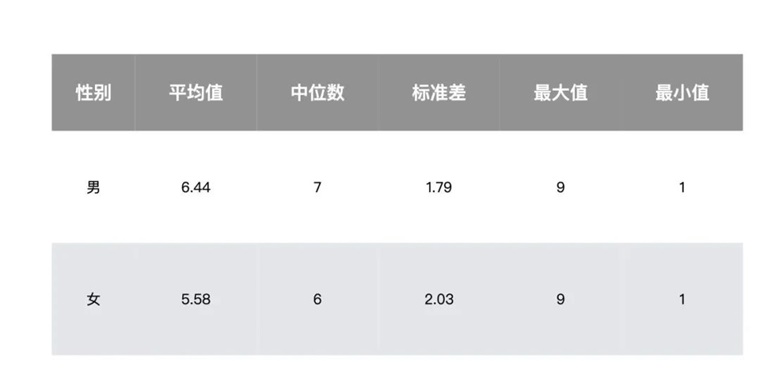
这些统计数据来自 253 位人类。他们普遍受过高等教育,不少拥有硕博学历,属于较为典型的高学历高收入高认知群体。
大语言模型有多么像人?
整体测试结果,如下图所示:

26 道题目,GPT-3.5 答对 15 道;GPT-4 答对 23 道;文心一言答对 2 道。
需要提醒的是,这仅仅是一项早期工作,测试流程、测试方法都有很多可以完善之处,未来结论随时会被推翻。
由于时间缘故,我们并没有前三类任务人类的测试结果数据,但按照过往的经验数据,大约在 40%-60%左右的正确率,如果我们略微高估,前三类任务 17 道题总计估算为答对 10 道题,加上第四类任务,人类大约答对 6 道。最终将人类的正确率估算为 26 道题目,答对 16 道。正确率大约为 62%。
62%,这也许就是什么时候,你觉得一个大语言模型像是一个真正的人一样的临界值。GPT-3.5 接近这个数值,所以人们被它大大地震惊住了。而 GPT-4 远远超越了这个值。
而百度的文心一言,只有 8%。路漫漫其修远矣。
给百度研发团队的一点小建议
不懂 NLP 的吃瓜群众,其实对百度 NLP 团队做出的努力,一无所知。我说个事实,大家就明白了。在中文自然语言处理领域,百度提供的 NLP 开源项目是数量最多的、维护最勤奋的、质量最好的。包括我带队研发的写匠项目,调用的也是百度 NLP 团队开发的分词开源包。
但是,文心一言表现这样,我觉得还是无法简简单单地用研发时间不足来解释、产品是第一版上线来敷衍。这类话可能拿来敷衍李老板可以,但是敷衍全球同行非常危险。
我怀疑,百度该项目的研发团队,极可能走错路线了。作为一名既懂认知科学又懂 NLP 的从业者,我觉得,以百度的技术实力,表现不至于这样。极可能是团队领导者定错目标了:拿到尽可能多的知识单元。
所以,新品发布会上,从 CEO 到 CTO,两位专家,还在拿百度拥有全球最大的中文知识单元说事。
但是,这压根不是 GPT-4 令人震惊的原因啊!!!
GPT-4 这类产品真正令人震惊的是,从 GPT-3.5 开始,它真的像一个人类了。
这才是形成全球性碾压式传播的根本。
这是完全不同的另一种开发目标。也就是,如何让 GPT-3.5 更像是一个人类,拥有人一样的思维能力,能够更快地自我学习、自我纠错。
中文知识单元的数量,在这个事情上毫无意义啊。
好比,我们要教会一个三岁的小朋友尽快学会说话,这个时候,有两个重要任务:
1)生命:让她尽快明白语义、语音之间的各类规则以及如何用语义、语音表达一个物理世界。
2)生态:我们是想方设法给她在家里创造一个有助于孩子学说话的生态。比如,我雇佣阿姨带小美妞的时候,第一考虑就是这阿姨爱不爱说话,外不外向。显然,一个喜欢说话、外向的阿姨,更容易带动小美妞说话。
结果,百度该项目团队的做法好比是,直接给一个三岁的小朋友扔了一千万吨词典,你背着词典走路吧。
生命何在?生态何在?
如果始终沿着这条技术路线走下去,我怀疑在 OpenAI 团队开源之前,不可能产生一个近似于数字生命的产品。
而 OpenAI 团队是将大语言模型当作真正的生命来对待,从构建一个数字生命的基本机制开始设计,一切工作都是围绕两个基本出发点:
1)生命:尽量促进“智能”的自发涌现;
2)生态:尽量设计一个促进有助“智能”诞生并发育的生态。
在早期,这个数字生命很幼稚,但过了千亿参数级别之后,很多早期打好的良好基础,就会带来极其多的“智能”涌现。好比小朋友从三岁学说话,长大之后,流利使用语言完成诸多大事。
我们不能在还没有涌现“智能”之前,就急匆匆地去卖应用、搞数据对接。那压根与 GPT-4 不是一类产品啊。
我们究竟要的是一个数字生命,以及这个新兴的数字生命与生态带来的新世界;还是又多了一个更方便地查询知识单元的工具。
我相信答案不言而喻。
正如我七年前在文章:文末所写的一样:
其实,不可思议之事才是硅谷与中关村的区别。创业者生来当作不可思议之事,而非可以看见未来的事。
这份小小报告及建议,希望对如今蜂拥而入大语言模型研发领域的团队,略有启发。也期待中国诞生足够多、足够好的数字生命,带着国人一起步入新世界。
阳志平本文使用写匠创作,2023-03-18
编者按:本文转载自微信公众号:心智工具箱(ID:Mindnote),作者:阳志平
未经允许不得转载:头条今日_全国热点资讯网(头条才是今日你关心的) » 文心一言的理性思维能力距离 GPT-4 差多少?我们第一时间测试了一下








